04. Speed/Accuracy Tradeoff
Speed vs Accuracy
As presented in the Canziani analysis, two conclusions are helpful when considering the speed and accuracy tradeoff for a robotic systems design that uses DNN inference on a deployed platform such as the Jetson:
- Accuracy and inference time are in a hyperbolic relationship
- The number of operations is a reliable estimate of the inference time.
If the system is supposed to be able to classify images that are included in the 1000 classes from ImageNet, then all that is needed is to benchmark some of the inference times on the target system, and choose the network that best meets the constraints of inference time or accuracy required. For example, if the following chart characterizes inference speed vs accuracy, and the system requires an accuracy of at least 80%, then the best fps we can hope for is about 10 fps as an upper bound. If that is acceptable, the system can be built using a known architecture trained on ImageNet.
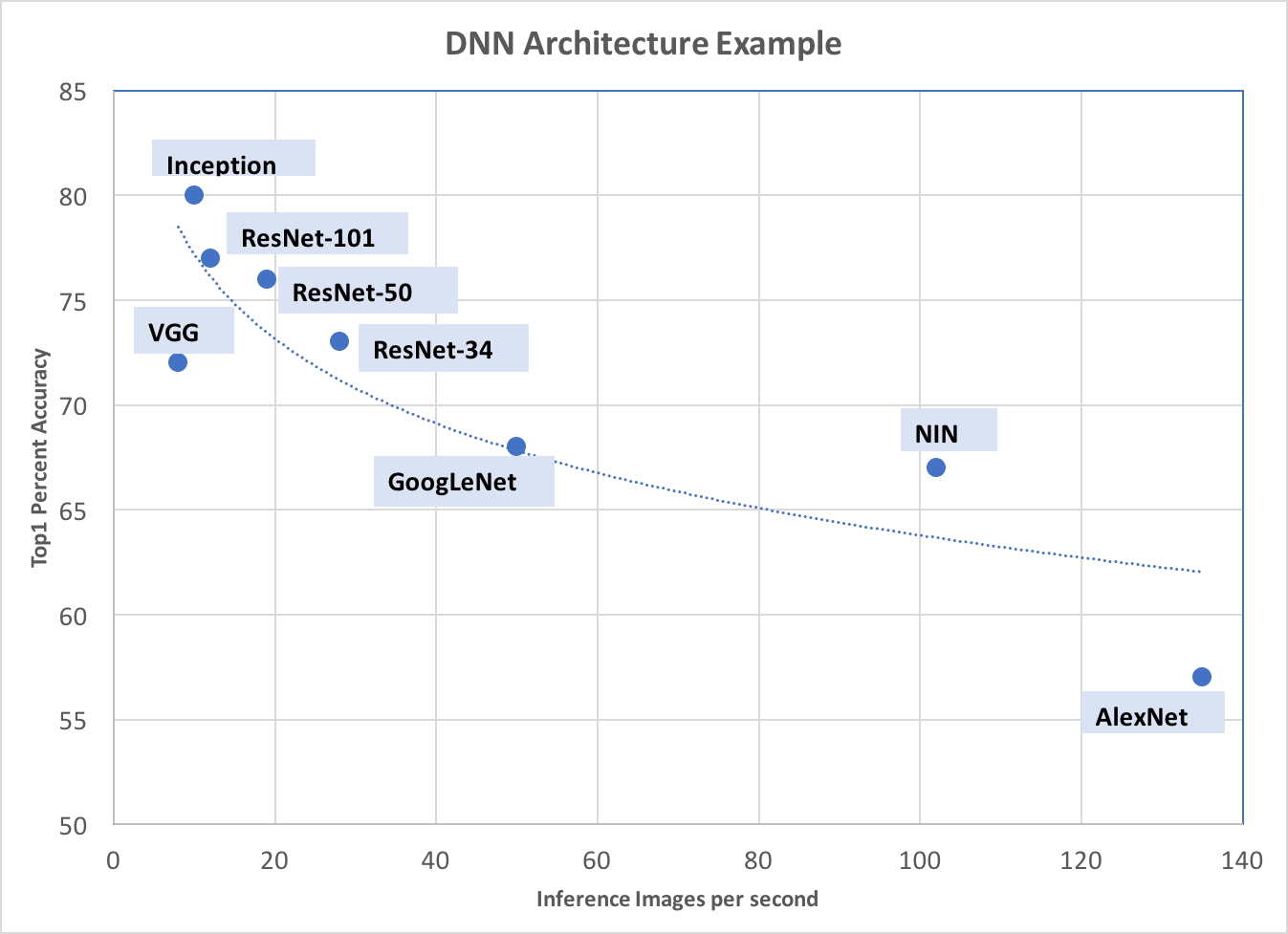
If 10 fps at 80% accuracy isn’t good enough, some other possibilities exist that may satisfy the constraints without redesigning a new network architecture:
- Redeploy to a higher performance hardware platform with improved operation execution time
- Upgrade the software platform with an optimized release that affects inference time
- Increase the accuracies by customizing the data to a smaller number of relevant classifications
Improved Hardware Platforms
As processors improve and state-of-the art features are added to improve execution time of operations, inference speed improves linearly too. For example, the Nvidia Jetson TX1 and TX2 are benchmarked against each other in the following table. The relative speedup in inference for GoogLeNet for batch=2 at Max Clock is 201/141, or 42%.

Improved Software Platforms
Changing out the hardware can be an expensive proposition and may not be an option. Often though, changes in the software platform that leverage optimizations can have at least as big an effect. For example, again looking at the Jetson TX2, the JetPack 3.1 and associated TensorRT improved software release sped up inference by a factor of 2!

Customized Data
So far, the improvements discussed have all been explained in terms of the benchmarks using famous architectures such as AlexNet, GoogLeNet, and ResNet, running the ImageNet classification set of 1000 image classes. That’s just a benchmark, though. These same architectures can be used with alternate data sets, possibly with better accuracy. For example, the ImageNet data set includes 122 different dog breeds among its labels. If it only matters for an application that the image is a “dog”, not which breed of dog, these images could be trained as a single class, and all the inaccuracies that might occur between categories would no longer cause errors.
Perhaps the application really is only concerned with picking items off of a conveyor belt and there are only 20 categories, but speed is a very important metric. In that case, the 20 classes could be trained (using an appropriately robust user data set), and a smaller, faster architecture such as AlexNet might provide a sufficient accuracy metric with the smaller number of classes.
These are all considerations that can be taken into account to inform the design process for a deployable system. In the end though, experimentation is still necessary to determine actual results and best optimizations.